In the domain Large Language Models (LLMs) such as ChatGPT, a new technique known as Retrieval Augmented Generation (RAG) is gaining prominence. This technique is designed to enhance a user's input by incorporating additional information from an external source. This supplementary data is then leveraged by the LLM to enrich the response it generates. In this blog post, we will look deeper into the core concept of RAG-fusion, which revolves around multiple query generation and re-ranking of results. For other methods that can improve RAG performance see my other Techniques to Boost RAG Performance in Production.
What is RAG-fusion?
The principle behind RAG-fusion is to generate multiple versions of the user's original query using a LLM, and then re-rank the results to select the most relevant retrieved parts.
NOTE: The term RAG in the name of the technique might be a bit misleading since "RAG-fusion" refers only to the first part of RAG - retrieval process.
How it works? For instance, the prompt template for this task might look something like this: "Generate multiple search queries related to: {original_query}", where {original_query} is a placeholder for the user's original query. This step enables the model to explore different perspectives and interpretations of the original query, thereby broadening the range of potential responses.
Re-ranking: A Crucial Step
The next vital step in the RAG-fusion process is re-ranking. This step is critical in determining the most pertinent answers to the user's query. The re-ranking process, often referred to as Reciprocal Rank Fusion (RRF), involves collecting ranked search outcomes from multiple strategies.
Each document is assigned a reciprocal rank score. These scores are then merged to create a new ranking. The underlying principle here is that documents that consistently appear in top positions across diverse search strategies are likely more pertinent and should, therefore, receive a higher rank in the consolidated result.
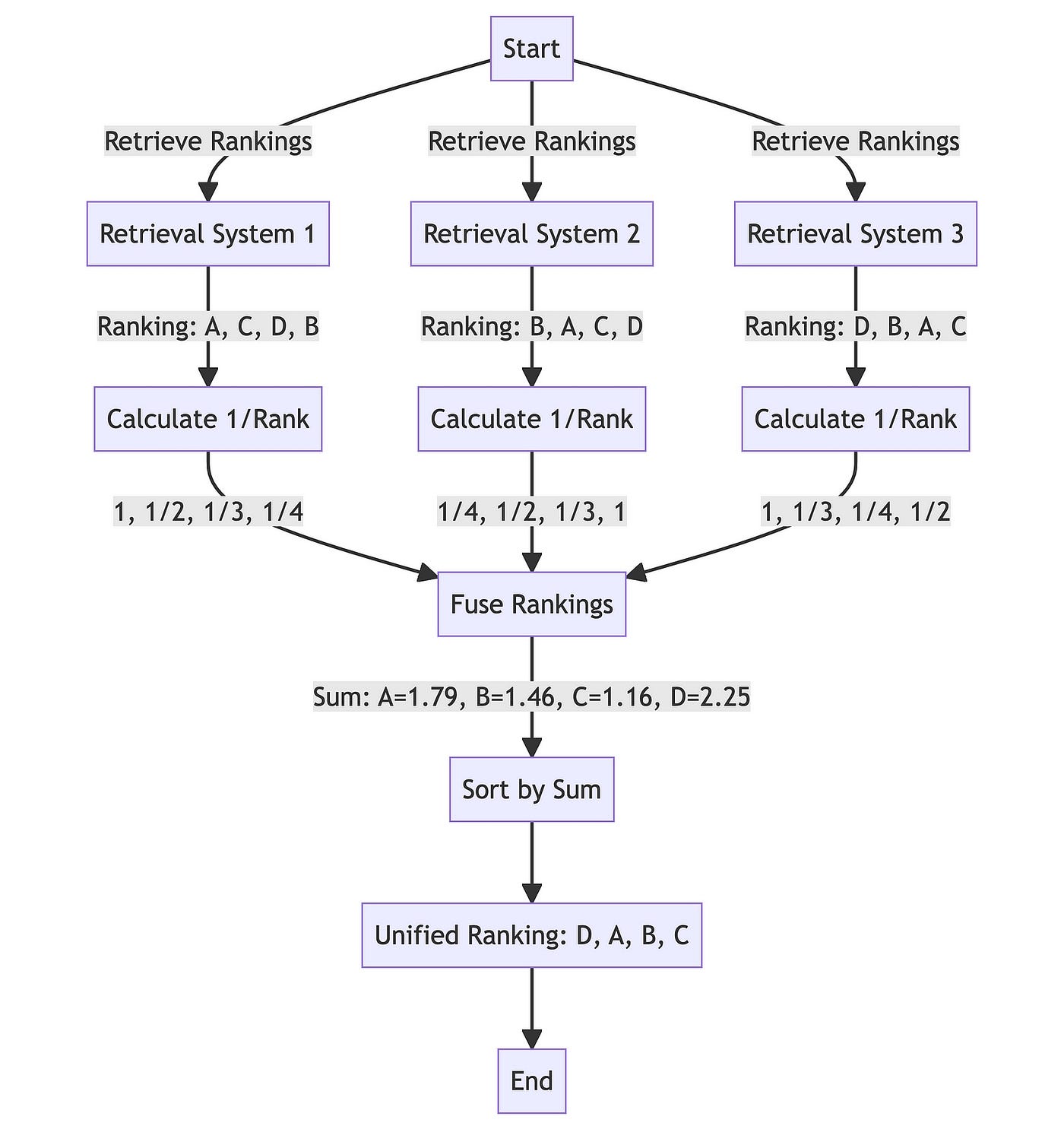 Figure 1. RAG fusion proces flow for ranking four documents A, B, C, D against three retrieval sources (can be three variants of the original user query). Source of image: Forget RAG, the Future is RAG-Fusion article by Adrian H. Raudaschl
Figure 1. RAG fusion proces flow for ranking four documents A, B, C, D against three retrieval sources (can be three variants of the original user query). Source of image: Forget RAG, the Future is RAG-Fusion article by Adrian H. Raudaschl
Why RAG-fusion Matters?
It provides a boost to the LLM's ability to generate more accurate, contextually relevant responses. By considering multiple interpretations of the original query and re-ranking the results, it ensures that the model's output is as closely aligned with the user's intent as possible.
RAG-fusion might be a powerful technique that brings together the strengths of large language models and advanced information retrieval strategies. By employing multiple query generation and re-ranking, it takes a leap towards making AI-powered systems more responsive, accurate, and user-friendly.
NOTE 1: For more methods that can improve RAG performance see my other Techniques to Boost RAG Performance in Production. NOTE 2: This technique is also referred as Query-Rewriting. You can find a section on that on LlamaIndex documentation (Query Transformation Cookbook)
- Understanding Retrieval-Augmented Generation (RAG) empowering LLMs
Edits:
- 2024-03-06: Added RAG fusion paper
- 2024-02-01: Add reference to LLamaIndex Query Transform Cookbook
References
- RAG-Fusion: a New Take on Retrieval-Augmented Generation
- GitHub - Raudaschl/rag-fusion - exemplary implementation
- Forget RAG, the Future is RAG-Fusion | by Adrian H. Raudaschl | Oct, 2023 | Towards Data Science
- RAG-fusion in LangChain: usage, template code
- Query Transformation Cookbook