2024-07-03
How does QLoRA works?
TL;DR
QLoRA (Quantized Low-Rank Adaptation) is a memory-efficient fine-tuning method for large language models. It uses a frozen 4-bit quantized base model with trainable adapters. During fine-tuning, only the adapters are updated, with gradients backpropagated through the quantized weights. Key innovations include 4-bit NormalFloat quantization, paged optimizers, and double quantization, all of which significantly reduce memory usage. This allows fine-tuning of large models on consumer hardware without compromising performance.
This article outline in brief idea of QLoRA. For the deeper understanding of QLoRA, I highly recommend reading blog post by the QLoRA authors explaining the QLoRA idea in a clear way.
Understanding QLoRA: Efficient Fine-tuning for Large Language Models
QLoRA (Quantized Low-Rank Adaptation) is an innovative technique that enables efficient fine-tuning of large language models. It combines several key components to reduce memory usage and computational costs without sacrificing performance. Let's break down how QLoRA works:
Core Components
- 4-bit Quantized Base Model: QLoRA starts with a pre-trained language model quantized to 4-bit precision. This dramatically reduces memory requirements compared to full-precision models.
- Low-Rank Adapters: Small, trainable modules are added on top of the frozen base model. These adapters capture task-specific information during fine-tuning.
- 4-bit NormalFloat: A novel quantization data type that maintains a normal distribution of values, preserving model quality better than traditional integer quantization.
- Paged Optimizers: A memory management technique that efficiently swaps optimizer states between CPU and GPU memory.
- Double Quantization: Further compresses the quantization constants, reducing memory usage even more.
How It Works?
- The base model is quantized to 4-bit precision and frozen.
- Low-rank adapters are added to each layer of the model.
- During fine-tuning, only the adapters are updated.
- Backpropagation occurs through the 4-bit weights into the adapters.
- Paged optimizers manage memory usage during training.
- Double quantization further reduces memory requirements.
This approach allows for fine-tuning of very large models on consumer-grade hardware, opening up new possibilities for researchers and developers working with state-of-the-art language models.
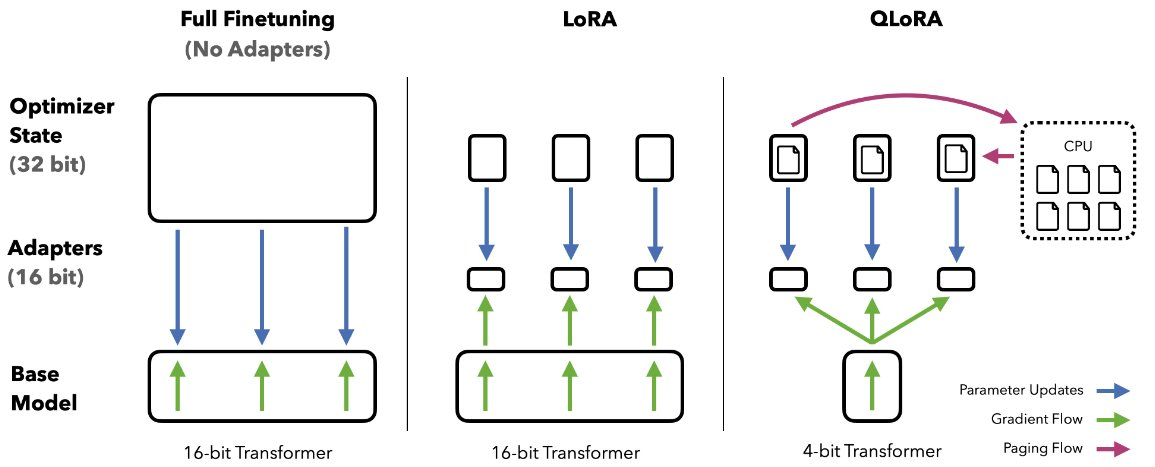 Figure from: QLoRA paper by Dettmers et al
Figure from: QLoRA paper by Dettmers et al
Three Innovative Techniques for Memory Efficiency
4-bit NormalFloat (NF4)
The QLoRA paper introduces the concept of 4-bit NormalFloat (NF4), a novel data type that is information theoretically optimal for normally distributed weights. NF4 is used for quantization in QLoRA, which aims to make large language models more accessible by reducing memory usage during fine-tuning. Unlike traditional 4-bit integer or 4-bit floating-point representations, NF4 is specifically designed for normally distributed weights, making it more efficient for certain tasks.
Paged Optimizers
In the context of QLoRA, paged optimizers are introduced to manage memory spikes during fine-tuning. These optimizers help mitigate memory usage by efficiently handling memory transfers between the GPU and CPU. While the specifics of paged optimizers are not covered extensively in the QLoRA paper, they play a crucial role in achieving memory efficiency.
Double Quantization
Double quantization is a technique used to reduce the average memory footprint in QLoRA. It involves quantizing not only the model parameters but also the quantization constants themselves. By applying double quantization, QLoRA achieves memory savings without compromising performance.
These innovations collectively contribute to QLoRA’s ability to fine-tune large language models efficiently while maintaining performance.
Further Reading
- Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA - blog post by the QLoRA authors explaining the QLoRA idea in a clear way.
- Original QLoRA paper by Dettmers et al (2023)