
Interpretability in machine learning is a complex and multifaceted topic. It refers to the ability of a model to explain its decisions and predictions to humans in a way that is understandable and meaningful. However, there is currently no agreed-upon definition or method for measuring interpretability.
Three levels of evaluating interpretability
Doshi-Velez and Kim (2017) propose a framework for evaluating interpretability at three levels: application level, human level, and function level.
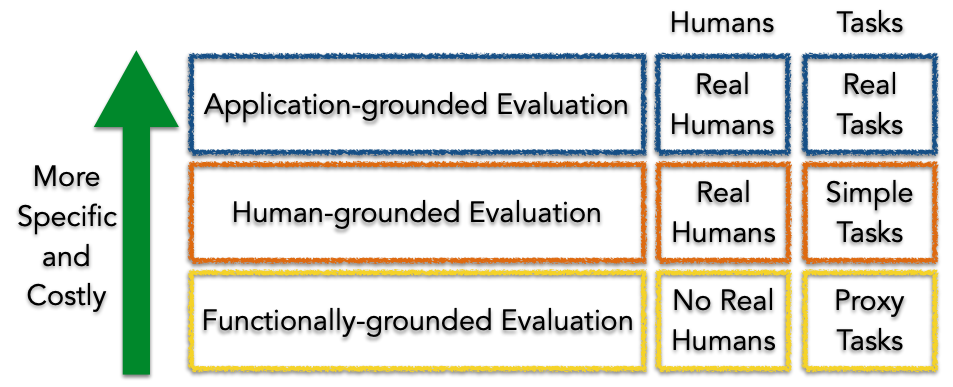 Figure 1. Taxonomy of evaluation approaches for interpretability, source: Doshi-Velez and Kim (2017)
Figure 1. Taxonomy of evaluation approaches for interpretability, source: Doshi-Velez and Kim (2017)
Application level
At the application level, interpretability is evaluated by testing the explanation in the context of the real-world task for which the model was developed. For example, in the case of a fracture detection software that uses machine learning to locate and mark fractures in X-rays, radiologists would test the software directly to evaluate the model. This approach requires a well-designed experimental setup and an understanding of how to assess the quality of the explanations. A good baseline for this evaluation is always how well a human would perform at explaining the same decision.
Human level
The human level evaluation is a simplified version of the application level evaluation. Instead of testing with domain experts, experiments are conducted with laypersons. This approach is more cost-effective and allows for more testers to participate. For example, a user might be shown different explanations and asked to choose the best one.
Function level
The function level evaluation does not require human participation. This approach is best suited for models that have already been evaluated at the human level by others. For example, it may be known that decision trees are well understood by end-users. In this case, a proxy for explanation quality might be the depth of the tree. Shorter trees would receive a higher explainability score. However, it is important to ensure that the predictive performance of the tree remains good and does not decrease too much compared to a larger tree.
Tools and methods for Interpretability
It's also worth noting that there are other approaches for evaluating interpretability, like using intrinsic and extrinsic evaluation metrics, as well as using techniques like saliency maps, LIME, SHAP, etc. These methods allow us to understand the feature importance and decision path of a model and evaluate the interpretability of a model.
Overall, the evaluation of interpretability is an active area of research, and there is no one-size-fits-all approach.
References:
- Doshi-Velez, Finale, and Been Kim. “Towards a rigorous science of interpretable machine learning,” no. Ml: 1–13. http://arxiv.org/abs/1702.08608( 2017).
- Christoph Molnar, Interpretable Machine Learning. A Guide for Making Black Box Models Explainable (2019). Available here.
Any comments or suggestions? Let me know.